简介
开发项目中用到了一致性哈希算法,并未系统总结过相关知识,趁此机会总结下。
一致哈希 是一种特殊的哈希算法。在使用一致哈希算法后,哈希表槽位数(大小)的改变平均只需要对 K/n 个关键字重新映射,其中 K 是关键字的数量,n 是槽位数量。然而在传统的哈希表中,添加或删除一个槽位的几乎需要对所有关键字进行重新映射。 --Wikipedia
通俗点说,一致性哈希算法是分布式系统中常见的算法,一个分布式的存储系统,要将数据存储到各个节点上,如果采用普通的 Hash 方法,将数据映射到具体的节点上,如 key%N,key 是数据的值,N 是机器节点数,分布式系统每个节点都有可能失效,并且新的节点很可能动态的增加进来,这样的话普通的哈希取模算法会造成缓存的巨大振荡,几乎所有的数据映射都会无效。
原理
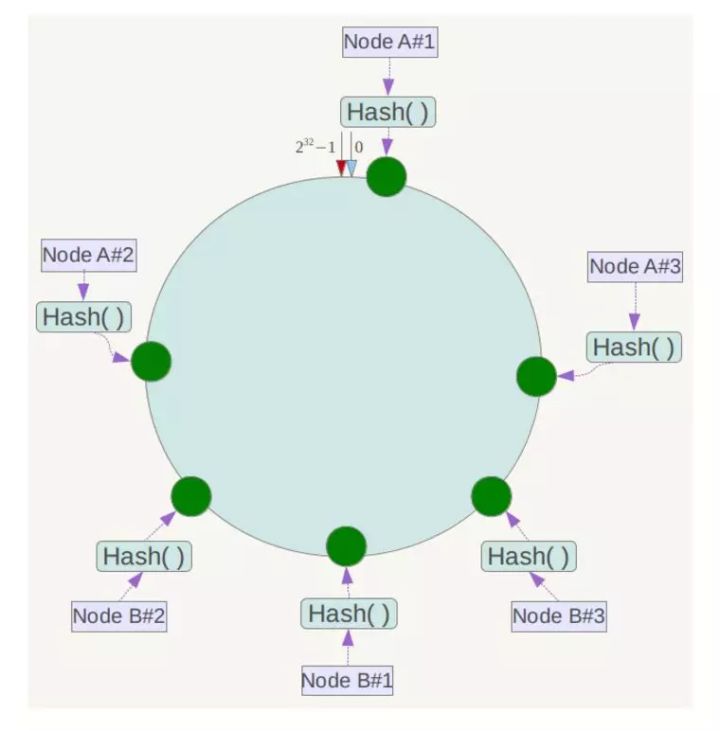
如下图,一个 Hash 环上值空间为 0 - 232 ,按顺时针方向组合,上有 A、B、C、D 四个 Hash 出来的节点。
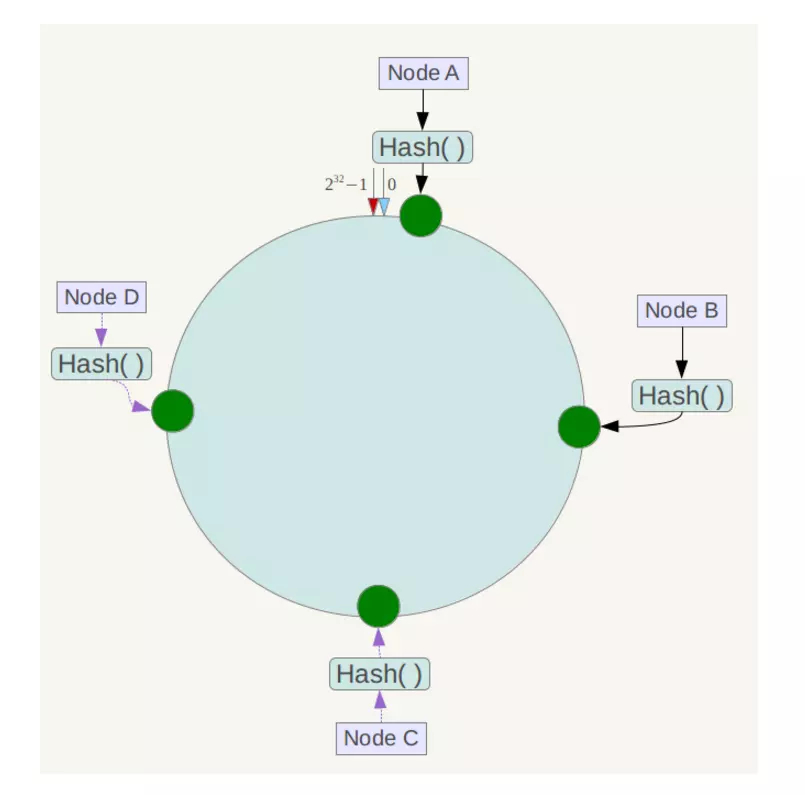
当定位某个 key 的位置时,使用相同的 Hash 函数计算出哈希值,并按顺时针找到相应节点区间,顺时针的下一节点即为其相应的服务器。
假设有 Object A、Object B、Object C、Object D 四个 key,在使用同样的 Hash 函数计算后,其位置如下图:
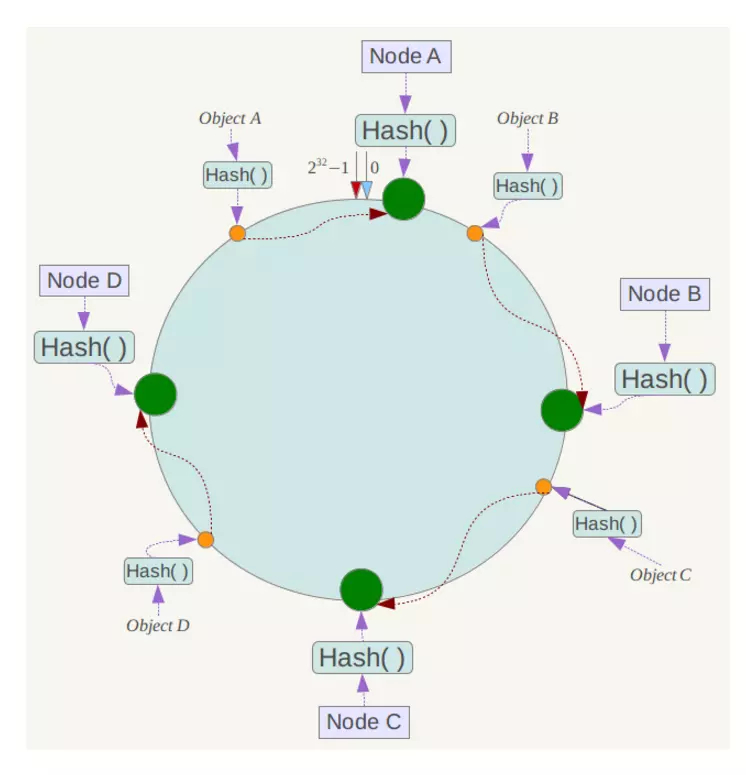
则顺时针寻找,Object A会被定为到 Node A 上,Object B 被定为到 Node B 上,Object C 被定为到 Node C 上,Object D 被定为到 Node D 上。
此时如若节点 C 宕机,则只会影响节点 B 到 C 之间的数据,其被定位到 D 节点上,而 A、B、D 上的原数据不会被影响,具有较好的容错性。
如果是新加一个节点 X,如下图:
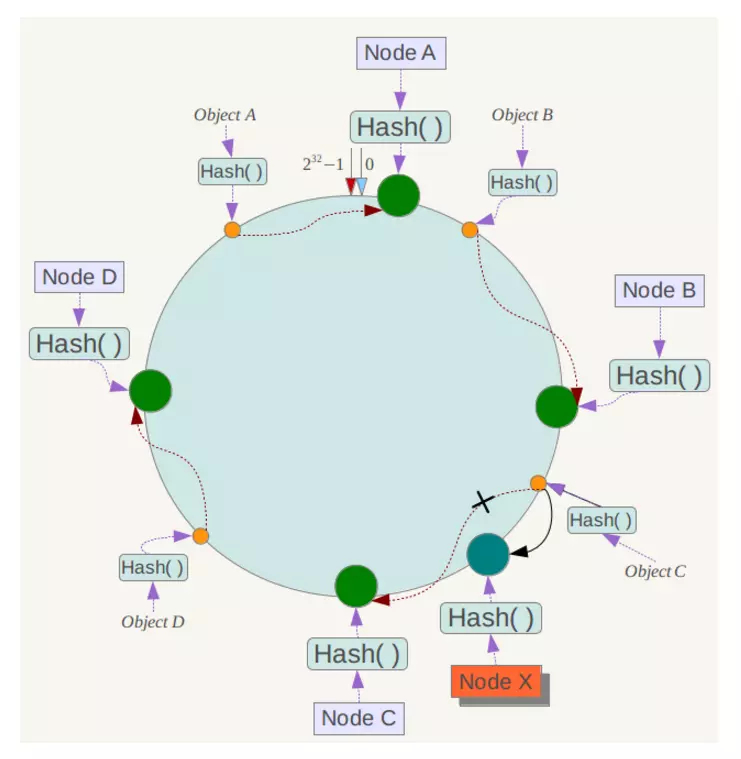
受影响的数据为节点 B 到 C 之间的,具有良好的可扩展性。
Hash 环的数据倾斜问题
当 Hash 环上节点数量较少时,很可能会发生很多数据被定位到其中一台上,其他节点数据极少的情况,如下图:
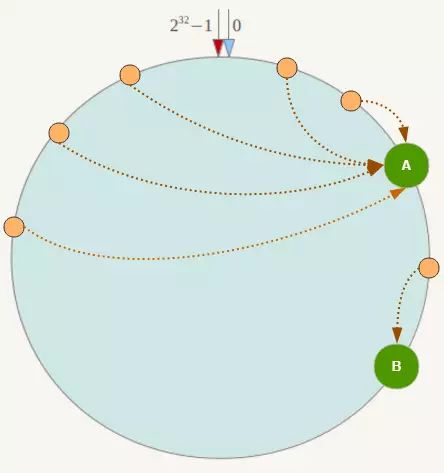
可以引入虚拟节点,即每台服务器虚拟出几个节点,这样可以尽可能的均匀分布,如下图:
One comment
这篇文章不错!